
Scheefheid
Als men gegevens verzamelt over een kenmerk in de praktijk, dan veronderstelt men soms dat deze gegevens normaalverdeeld zijn. Kenmerkend voor een normaalverdeling is dat het gemiddelde precies in het midden ligt en dat de verdeling aan beide kanten gelijkmatig afneemt. Dat is natuurlijk niet altijd het geval. De meest simpelste manier om na te gaan of een kenmerk normaalverdeeld is, is het uitprinten van de frequenties en uit de frequentieverdeling nagaan of deze op een normaalverdeling lijkt. Dit kan worden ondersteund door de verdeling te visualiseren: presenteer de gegevens in een histogram of een staafdiagram.
Andere indicatoren voor het normaalverdeeld zijn van een variabele is dat het gemiddelde, de modus en de mediaan allemaal gelijk zijn. Blijkt dit niet het geval te zijn, dan moet men concluderen dat de verdeling niet normaalverdeeld is.
Het zal zelden voorkomen dat de modus, de mediaan en het gemiddelde precies gelijk zijn en een visuele beoordeling is natuurlijk ook niet erg nauwkeurig. Het kan beter door de scheefheid (in het Engels: skewness) en de kurtosis te berekenen en te interpreteren.
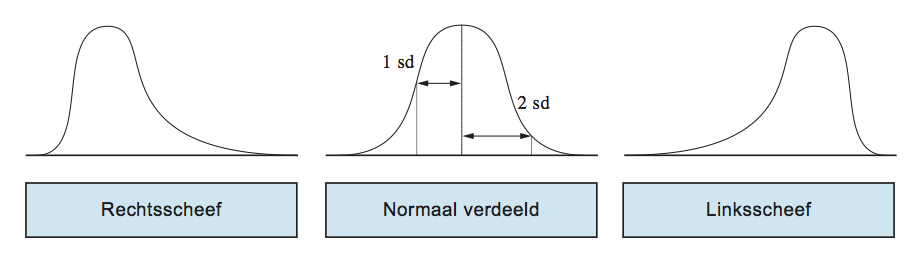
Bij scheefheid wordt een onderscheid gemaakt naar links-scheef en rechts-scheef. Bij links-scheef liggen er weinig waarnemingen links van het midden; het zwaartepunt ligt dus rechts van het midden. Men kan zich dit visueel voorstellen als een glijbaan, waarbij je aan de rechterkant naar boven klimt en aan de linkerkant naar beneden glijdt. Bij rechts-scheef is het juist andersom: er liggen weinig waarnemingen aan de rechterkant van het midden (zie illustratie).
De formule voor de scheefheid bestaat voornamelijk uit de derdemachten van de afzonderlijke x-waarden:

Een links-scheve verdeling heeft een negatieve waarde, terwijl een rechts-scheve verdeling een positieve waarde heeft. Ligt het gemiddelde precies in het midden dan is de waarde van de scheefheid 0.
De scheefheid is statistisch te toetsen waarmee aangegeven kan worden of de gevonden verdeling afwijkt van de normaalverdeling. Men doet dat gewoonlijk niet, omdat deze uitkomst geen of nauwelijks consequenties heeft voor de uit te voeren statistische analyses met deze variabele. Scheefheid wordt eigenlijk alleen maar gebruikt ter beschrijving van de variabele.
Copyrights
© Foeke van der Zee / BMOOO - Woordenboek onderzoek, methodologie en statistiek
Meer MOA
Kennispartners van Daily Data Bytes















MOA is een

Privacystatement, Cookieverklaring & Disclaimer, MOA© 2022